这学期一口气选了三门 AI 课(AI、模式识别、NLP),初衷就是想深入了解以后能更有底气地说“我不喜欢AI”(x
然后三门课内容高度重复,每个知识点平均听三遍。。。其中最近发生的重合是,人工智能实验先要写一个 RNN 做关键词提取,然后 NLP 课要用 BiLSTM+CRF 做中文分词,完了之后还要用 LSTM 做语言模型。。。
于是这位可怜的老 C++ 选手在用 C++ 写完了 KNN、决策树、PLA、逻辑回归、BPNN 之后,不得不在一个月内从 python 语法入门摸爬打滚到机器学习带师(x
这篇博客大概只是分享和记录,不是教程。我认为学 AI 最好的方式是在学校里上课(有老师带,有同学一起讨论),或者买本书来学。在网上找博客自学是很不靠谱的。
前置
做这些事的前置技能大概就是:学会 python、学会神经网络的理论框架。
一开始作为 C++ 选手也本能地纠结了一下既然 pytorch 也有 C++ API,为啥还要转 python 呢?大概考虑三个因素:
- 从速度来说:大家心中都有一个观念是“C++跑得快”,但是写起神经网络来,基本上都是在调库,时间瓶颈在于训练和反向传播的那些矩阵运算,线程优化和 GPU 算力才是硬道理。pytorch 底层也是 C/C++ 实现的,所以通篇都在调库的情况下,没有多大时间差。
- 从操作方便性来说:编程简便性是 python 优胜毫无疑问了,python 对于数据处理有更灵活的语法,还有巨多方便的库,例如一行 one-hot,例如许多课程可能要求先手写 BPNN,在 numpy 的支撑下 python 会从时间和简便性两方面吊打 C++。python 有包管理器这一点也很资瓷。
- 从环境来说:你周围的同学应该 98% 都会跟风用 python,这意味着如果你执意用别的语言,你将基本单打独斗,你们的讨论将变得困难,
你代码出了 bug 不会有人来帮你调。这点对于学生可能才是最应该考虑的,为了获得学习环境的兼容,一起跟风吧~
然后神经网络的数学基础,大概就是《最优化方法》一类的课程,最好手写一遍 BPNN,该造的轮子必须得造。
RNN 关键词提取
Task
数据集是 http://alt.qcri.org/semeval2014/task4/ 的 SemEval-2014,Laptop,里面有 3000 余条英文句子,给出了每个句子的关键词(或词组)。每个句子可能有多个关键词(或词组)。
以此训练一个模型,输入一个英文句子,可以找出句子的关键词。
模型准备
首先要将这个任务表示为具体的数学模型。
第一步是词嵌入。采用 100 维的 Glove 词向量(https://nlp.stanford.edu/projects/glove/),将每个单词及标点都换成相应的词向量,那么一个句子就是若干个 100 维向量组成的序列。
第二步是序列标注。怎样使得模型的输出能够表征句子的关键词?序列标注是一种方法。参考中文分词的序列标注法,给每个字标上 B,M,E,S 中的一个标记,B 表示分词开始,M 表示词语中间字,E 表示分词结束,S 表示单字词语。这个序列唯一对应了一种分词结果。
同理应用到关键词提取任务中,可以想到一种标注方法:N 表示非关键词,B 表示关键词开始,M 表示关键词中间词,E 表示关键词结束,S 表示单个关键词。这样就使得关键词提取变成了分类任务,输入一个句子,为每一个单词做分类。
以“NBMES”来标注虽然十分准确,但是标注较为复杂,数据集较小时训练效果不好。
一种改进是改为“NBM”标注,N 表示非关键词,B 表示关键词开始,M 表示关键词非开始位置。这与“NBMES”标注是等价的(二者是唯一对应的),但是化简了标注。
另一种改进是改为“IO”标注,I 表示是关键词,O 表示不是关键词。这种标注法比上述方法更简便,且变成了二分类问题,可以使用更多评测指标(例如 F1 分数)。但缺点是无法区分关键词组与连续单个关键词。
本次任务采用“IO”标注。检视本次数据集发现所有关键词(组)均不相邻,因此上述缺点在训练中不存在。在实际应用中,也并非一定要区分关键词组与连续单个关键词。
网络
句子的长度是变化的,不适合使用固定大小的全连接层。循环神经网络(RNN)可以有效应对这类数据。
(此处略去若干 RNN 原理。。。)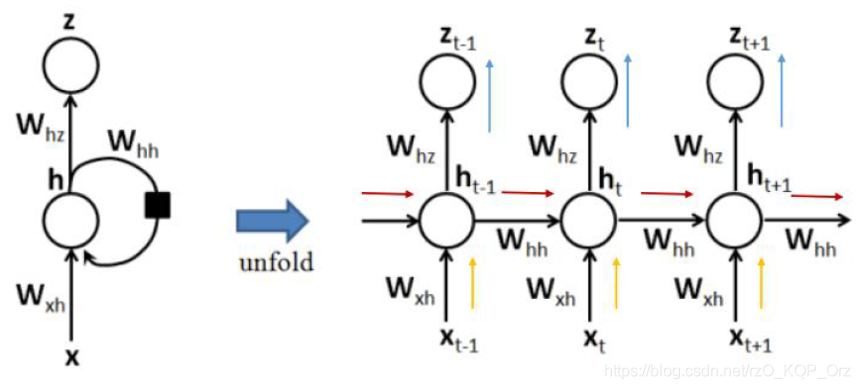
RNN 可以做许多扩展,例如:
- 多个 RNN 垂直叠加,成为多层 RNN;
- 再增加一层从右影响到左的隐状态,成为双向 RNN;
RNN 虽然理论上实现了当前状态与过往状态的联系,但对于时间相隔较长的过往状态保留的信息很少。同时,RNN 展开较深的时序时,存在梯度消失和梯度爆炸的问题。
LSTM 是一种改进的 RNN,在其结构中加入了许多控制门: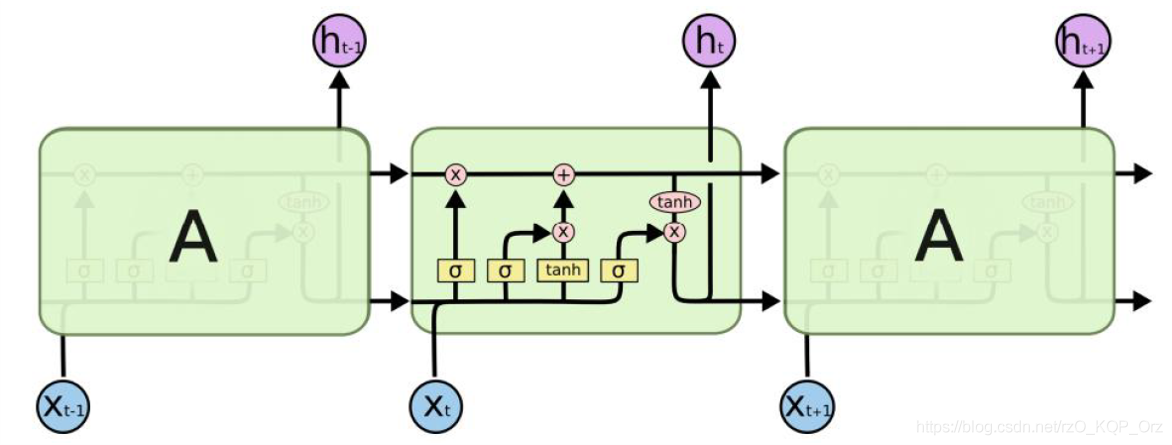

LSTM 新增了一层隐状态 $\mathbf C_t$。传统 RNN 通过 $\mathbf x_t$ 与 $\mathbf h_{t-1}$ 直接得到 $\mathbf h_t$;但在 LSTM 中,先通过 $\mathbf x_t$ 与 $\mathbf h_{t-1}$ 使用不同的权重和偏置分别算出遗忘门 $\mathbf f_t$、输入门 $\mathbf i_t$、输出门 $\mathbf o_t$,再使用遗忘门和输入门对 $\mathbf C_t$ 进行更新,最后用 $\mathbf C_t$ 和输出门得到 $\mathbf h_t$。
三个控制门矩阵都经过了 sigmoid 函数,因此元素都 $\in (0,1)$,用这些矩阵对别的矩阵做对应位置相乘求和,相当于控制别的矩阵的每个元素的保留程度。因此 $\mathbf C_t = \mathbf f_t \odot \mathbf C_{t-1} + \mathbf i_t \odot \mathbf g_t$ 这一项,就相当于控制 $\mathbf C_{t-1}$ 遗忘了多少、当前 $\mathbf g_t$ 记住了多少,是一种平滑移动。
代码实现
整份代码实现起来难度不大,主要难度在于学习如何使用 pytorch。就只放网络结构了,其实也都是调包侠。。。
1 | import torch |
还有数据的预处理也是比较繁琐的,但是也只是编程实现上的难度,不是算法设计的难度。
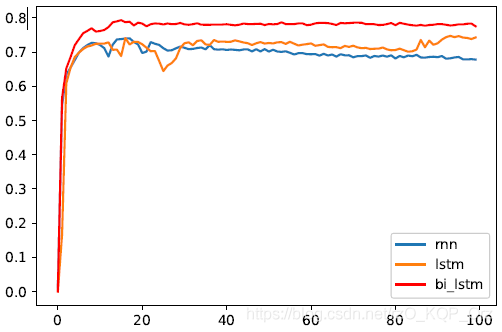
效果
因为序列标注用了二分类,因此结果的评价就用 $F1$ 分数了
BiLSTM+CRF 中文分词
Task
使用 BiLSTM+CRF 分词模型,在 SIGHAN Microsoft Research 数据集上进行中文分词的训练和测试。
已标注数据集的每一条数据是一个中文句子,词之间用两个空格隔开。
整体设计
依然是采用序列标注的方法来做分词,为每个字标上 B,M,E,S 中的一个标记,B 表示分词开始,M 表示词语中间字,E 表示分词结束,S 表示单字词语。这个序列唯一对应了一种分词结果。
模型的整体框架为:对于一个句子,设长度为 $l$(以 UTF8 字符数量计),依次通过以下步骤:
- 将每个 UTF8 字符替换成字向量,得到长度为 $l$ 的字向量序列;
- 通过 BiLSTM 得到长度为 $l$ 的分数向量序列(分数向量是一个 4 维向量,分别代表该字表为 B(begin),M,E,S 的分数);
- 通过 CRF 得到长度为 $l$ 的序列标注;
- 基于序列标注得到分词结果。
采用 300 维的预训练字向量 sgns.context.word-character.char1-1.dynwin5.thr10.neg5.dim300.iter5,该向量集含有单字、词语、标点符号、英语缩写、希腊字母等诸多元素,但只取单字和标点符号用于本次任务。
本次任务中,若句子含有未被字向量覆盖的字符,则该数据作废。经验证,训练集有 1 条数据被作废,测试集数据全部有效。
BiLSTM+CRF
LSTM 上面已经写过了,BiLSTM 就是双向的 LSTM。
LSTM 的输出是 4 维分数向量的序列,进行归一化可以直接得到每个字的标签预测概率分布。但是结合传统概率模型可以使上下文关联效果更好,因此 LSTM 之后采用 CRF。
CRF 有两个任务:训练的时候求出给定序列标注的后验概率,并以其负对数作为损失函数进行梯度下降;测试的时候通过输入的分数向量序列求出概率最大的序列标注。
但实际上许多现有的 CRF 实现方法做的并不是真正的概率模型,而是用一种标注方案的分数除以所有标注方案分数和作为该方案的“概率”。以下先按概率模型作分析,再说明现有 CRF 实现方法的分数模型。
概率模型
训练时,设给定序列标注为 $y_1,\cdots,y_l$,CRF 的输入序列为 $\mathbf x_1,\cdots,\mathbf x_l$,则后验概率为
求解该式只需将 $i$ 从 $1$ 到 $l$ 遍历一遍,把所有用到的概率乘起来即可。其中 $P(y_i|\mathbf x_i)$ 为发射概率,可以将向量 $\mathbf x_i$ 归一化之后取 $y_i$ 那一项;$P(y_i|y_{i-1})$ 为转移概率,可以用矩阵 $\mathbf A$ 来求,$A_{ij}$ 表示由标签 $i$ 转移到标签 $j$ 的概率,该矩阵与其他网络参数一起参与训练。
测试时,已有输入序列 $\mathbf x_1,\cdots,\mathbf x_l$ 和标签转移矩阵 $\mathbf A$,则通过动态规划找到最大概率的标注方案。设 $dp_{i,j}$ 表示已经考虑了序列的前 $i$ 项,第 $i$ 项选择标签 $j$,的最大概率,则
记录 DP 的转移路径,最后选最大的 $dp_{l,j}(j=1,2,3,4)$ 根据转移路径倒推即得到标注结果。
实现的时候应当对概率取对数,将乘法变为加法运算,避免精度问题。
分数模型
以 torchcrf 的实现为例:所有的概率都被换成分数,后验概率改为后验分数;发射概率 $P(y_i|\mathbf x_i)$ 替换为发射分数,直接取向量 $\mathbf x_i$ 中 $y_i$ 那一维的值;转移概率矩阵 $\mathbf A$ 替换为转移分数矩阵,$A_{ij}$ 表示由标签 $i$ 转移到标签 $j$ 可以获得的分数。上面两式的概率乘法改为分数相加。
训练时还需计算一个“所有标注方案的分数和”,可以用类似递推算出。
计算损失函数的时候,定义给定标注序列 $y_1,\cdots,y_l$ 的“概率”为
取对数则为
代码实现
依然是大调包,只放网络结构了。
网络里的结构依次为:BiLSTM,全连接层,CRF。在训练的前向过程中,CRF 层是计算“概率”的对数,得到结果取反为损失函数;而测试的前向过程,则是动态规划解码,直接返回标注序列。
1 | import torch |
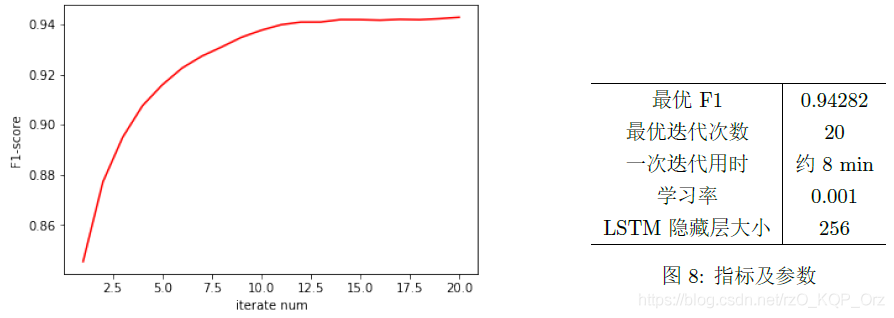
结果
评估指标为 F1:
LSTM 语言模型
Task
语言模型是机器对于语言本身的掌握程度,形式化地定义就是,给定一个句子,计算这个句子的概率。
这东西的应用,比如,翻译标准“信达雅”中的“达”,即目标语言的通顺流畅,就是语言模型;比如,输入法或者百度搜索框里面输入了一个词,系统就会联想下一个词,或者联想了一个句子,这个是文本生成。
本次任务就是文本生成。给定初始词,用这个词生成下一个词,再用新生成的词生成下一个词,再用新生成的词生成下一个词……直至生成\
原理与步骤
模型核心为一个单向 LSTM,输入是一个句子转化成的词向量序列,训练时通过 LSTM 得到相同长度的预测概率分布序列(序列的每一个元素是词表大小的向量,表示预测为词表某个词的概率分布),以与正确文本的逐词交叉熵作为损失函数进行反向传播;测试时给定初始词,不断用上一个词通过 LSTM 生成下一个词,直至生成 \
词表
词表构建有两种方法,一是沿用上一个 Task 的 300 维预训练字词向量 sgns.context.word-character.char1-1.dynwin5.thr10.neg5.dim300.iter5,它包含了绝大部分常用词语。但该方法有很多缺点:
- 词表有 63 万个词,搭建网络对显存需求很大;
- 训练集被词表完全覆盖的句子只有 39231 条,意味着超过一半的句子存在“未知词”;
- 观察词表发现 150000 以后的词并不常用(如各种网络用语),几乎不会出现在训练集里,造成浪费。
第二种方法是仅给训练集里出现的词语进行编号,用 pytorch 的 embedding 层得到词向量,随其他网络参数一同训练。训练集的词语约 88000 条,相比上一个方法能有效减小网络大小,且完全覆盖训练集。
本次两种方法都尝试了一遍,一是截取预训练词表前 150000 个词,且训练集只保留被词向量完全覆盖的句子(否则预测出来的句子也会大量出现“未知词”);二是给训练集的词编号并使用 embedding 层,词向量跟随网络一起训练。
实现
网络结构
网络里的结构依次为:(embedding),LSTM,全连接层。词表大小为 vocab\_size,embedding 层维度为 vocab\_size$$\to$$embedding\_dim,LSTM 层维度为 embedding\_dim$$\to$$hidden\_dim,全连接层维度 hidden\_dim$$\to$$vocab\_size。
若采用预训练词向量则没有 embedding 层。
由于显存的限制,hidden\_dim 只能开到 350,造成该网络是比较畸形的网络。(后面全连接层输出至少是 8 万维)
1 | import torch.nn.utils.rnn as tRnn |
测试
由于 pytorch 比较难实现直接通过上一个词得出下一个词,故用以下方式实现:
设当前句子为 $sentence$(是一个词序列),初始时 $sentence$ 为输入的初始词。每次将 $sentence$ 输入网络,得到相同长度的输出 $predict$,取 $predict$ 的最后一个词添加到 $sentence$ 的末尾,若该词不为 \1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def test(initWord, myNetwork) :
if not(initWord in wordVec) :
print('This word is not in training set!')
return
sentence = [wordVec[initWord]]
myNetwork.eval()
while True:
data = torch.tensor([sentence])
predict = myNetwork.forward_test(data,[len(sentence)])[0]
lastWord = predict[-1]
sentence.append(lastWord)
if (lastWord==0) :
break
for i in sentence :
print(vecWord[i],end='')
print()
结果
迭代 30 次,取每次 epoch 的所有句子的平均交叉熵,对比如下: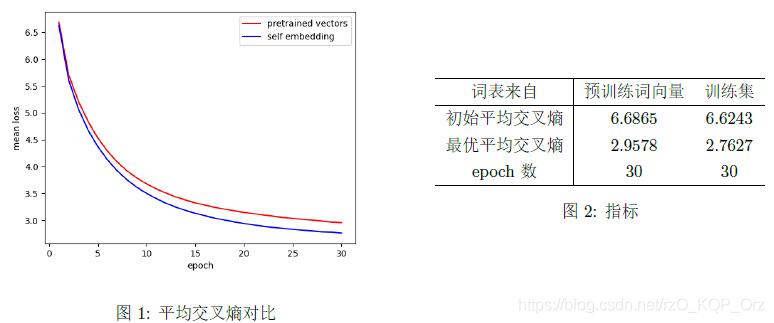
可以看到,使用训练集作为词表的效果会略微好些,差距大约在 15 次 epoch 时被拉开。
生成句子的测试效果如下:



4 个图分别称作图 1 ~ 图 4,分别为预训练词向量测试效果1、预训练词向量测试效果2、训练集embedding 测试效果1、训练集embedding 测试效果2。
整体来看,二者都能正常执行生成句子的过程,生成的句子大致通顺,但存在大量语法问题,句子成分缺失明显,句意基本都不通顺。
相比来看,在测试集 1 上训练集 embedding 的效果(图 3)要好于预训练词向量的效果(图 1),后者出现了大量的重复词语和句子,且句子通顺程度弱于前者;测试集 2 虽然整体来看是训练集 embedding 更通顺(图 4),但预训练词向量的结果(图 2)中有“给北京军区某给水工程团记一等功。”这样完全符合语法、句意完全通顺的句子。
以图 3 为代表,可以发现生成的句子具有如下特点:
- 有关党和政治的语句特别多,与党和政治相关的开头(如图 3 的前三句)效果要好于其他句子,甚至用“诗”作开头都能扯到党的建设。这是明显的训练集特征,训练集大部分句子是与党和政治相关的。
- 部分句子会使用训练集原文。如图3 的“美国”开头的句子,这条新闻可以在百度搜到原文。
- 稍有典雅性。如图 3 的后三句——“墨色生几分侵蚀”“诗才敏捷,音韵铿锵”等,尽管这完全不足以进行文学分析。